
Nuxt 3에서는 클라이언트와 서버 환경 모두에서 데이터를 가져오는 다양한 방식($fetch, useFetch, useAsyncData)을 제공합니다.
그런데 왜 같은 목적을 위한 것처럼 보이는 이 세 가지 도구가 필요할까요? Nuxt 3를 처음 접하는 개발자라면 어떤 것을 선택해야 할지 고민하게 될 수 있습니다. 이 게시글은 이러한 헷갈림을 해소하는 데 큰 도움이 될 것입니다.
데이터 호출 시 각 도구가 특정 상황에서 효율성과 유연성을 제공하는지를 이해하는 것이 중요합니다. 이를 통해 더욱 효율적이고 성능이 뛰어난 애플리케이션을 개발할 수 있습니다.
각 방법을 더 자세히 살펴보기에 앞서, 세 가지 메소드를 간단히 요약하자면 다음과 같습니다:
- $fetch: 네트워크 요청을 수행하는 가장 기본적인 방법으로, 클라이언트와 서버 모두에서 사용할 수 있습니다. 그러나 중복 호출 문제가 있어 클라이언트 사이드 상호작용에 더욱 적합합니다.
- useAsyncData: 서버 사이드 렌더링(SSR)에 적합한 방식으로 비동기 데이터를 처리할 수 있는 composable입니다. 이 메소드는 Universal Rendering에서 데이터를 한 번만 가져와 데이터 요청을 최적화하고, 서버 측 렌더링에서 데이터 상태를 유지합니다.
- useFetch: useAsyncData('', () => $fetch(url))을 편리하게 사용할 수 있도록 감싼 래퍼입니다.
이번 게시글에서는 각 옵션을 자세히 살펴보고, 상황에 따라 어떤 도구를 선택하는 것이 가장 적합할지 알아보겠습니다.
$fetch
Nuxt는 HTTP 요청을 위한 $fetch 메소드를 전역적으로 노출합니다. $fetch를 통한 데이터 패칭이 기본값임을 알 수 있습니다.
$fetch는 useAsyncData 및 useFetch와 대비되는 가장 중요한 특징이 있습니다. 바로 상태를 서버에서 클라이언트로 전이하지 않는 것입니다.
이는 어떤 결과를 초래할까요?
Nuxt는 서버와 클라이언트 환경 모두에서 범용 코드를 실행할 수 있는 프레임워크입니다. 만약 Vue 컴포넌트의 setup 함수 내에서 $fetch를 사용해 데이터 패칭을 하게 되면, 데이터를 두 번 요청하는 문제가 발생할 수 있습니다.
첫 번째는 HTML을 렌더링하기 위한 서버 측 요청이고, 두 번째는 클라이언트에서 HTML이 Hydrate될 때 이루어지는 요청입니다.
이러한 상황은 하이드레이션 불일치(Hydration Dismatch) 문제를 초래할 수 있으며, 예기치 않은 동작이나 성능 저하로 이어질 수 있습니다.
간단한 GET API를 호출하는 예시로 결과를 살펴보겠습니다.
<script setup lang="ts">
const $fetchData = await $fetch("https://jsonplaceholder.typicode.com/todos/1");
console.log("$fetchData", $fetchData);
</script>
위의 코드는 HTTP 요청이 서버와 클라이언트 모두에서 중복 호출됩니다. 콘솔에는 API 호출 결과가 두 번 출력되는 것을 확인할 수 있습니다.
이를 방지하기 위해 등장한 것이 바로 useAsyncData와 useFetch Composable입니다. 이 두 메소드는 서버에서 API 호출이 이루어질 경우, 데이터 payload를 클라이언트로 전달하여 중복 호출 문제를 해결합니다.
Nuxt 공식 문서에서도 컴포넌트 데이터를 패칭할 때는 useFetch 또는useAsyncData + $fetch를 사용할 것을 권장하고 있습니다.
We recommend to use useFetch or useAsyncData + $fetch to prevent double data fetching when fetching the component data.
그렇다면 $fetch는 언제 사용해야할까요?
$fetch는 클라이언트 사이드 상호작용(이벤트 기반)에 적합합니다. 예를 들어, 아래와 같은 코드에서는 사용자 반응에 따라 클라이언트 사이드에서만 API를 호출하게 되므로 $fetch의 사용이 적절합니다.
const postURL = "https://jsonplaceholder.typicode.com/posts"
const contactForm = () => {
$fetch(`${postURL}`, {
method: 'POST',
body: { hello: 'world' }
}).then(response => {
console.log('Response:', response)
}).catch(error => {
console.error('Error:', error)
})
}이와 같은 방식은 주로 POST, PUT, PATCH, DELETE와 같은 Method에 활용될 수 있습니다.
$fetch에 대한 더 자세한 내용은 Nuxt 공식문서에서 자세하게 확인할 수 있습니다.
https://nuxt.com/docs/api/utils/dollarfetch
$fetch · Nuxt Utils
Nuxt uses ofetch to expose globally the $fetch helper for making HTTP requests.
nuxt.com
useAsyncData
useAsyncData는 서버 사이드 렌더링(SSR)에 친화적인 방식으로 비동기 데이터를 처리할 수 있는 composable입니다.
이 기능을 사용하면 서버에서 데이터를 미리 가져와 클라이언트로 전달하여, 불필요한 클라이언트 사이드 요청을 줄일 수 있습니다.
기본 사용법은 다음과 같습니다:
<script setup lang="ts">
const data = await useAsyncData("todo", () =>
$fetch("https://jsonplaceholder.typicode.com/todos/1")
);
console.log("data", data);
</script>
useAsyncData의 리턴값에 대해 간단하게 요약하면 다음과 같습니다:
- data: 비동기 함수의 결과로 반환된 데이터
- refresh/execute: 데이터를 다시 불러올 수 있는 함수
- error: 데이터 가져오기에 실패한 경우의 에러 객체
- status: 데이터 요청 상태를 나타내는 문자열 ("idle", "pending", "success", "error")
- clear: 데이터를 초기화하고, 현재 진행 중인 요청을 취소하는 함수
- pending: 데이터가 요청 중인 상태 (Nuxt 최신 버전에서는 status에 포함)
이제 브라우저의 개발자 도구에서 네트워크 요청을 확인해보면, 클라이언트 단에서는 API 호출이 발생하지 않았음을 확인할 수 있습니다.
이는 API 호출이 서버에서 이루어졌으며, 서버에서 데이터를 미리 받아 클라이언트로 전달했기 때문입니다.


만약 서버에서 데이터를 가져오지 못한 경우(예: server: false 설정)에는 클라이언트 사이드에서 하이드레이션이 완료된 후 데이터를 불러오게 됩니다.
그런데, 어떤 원리로 서버와 클라이언트의 HTTP 중복 호출을 막을 수 있는 걸까요?
이를 가능하게 하는 핵심 요소는 Key Parameter와 refresh 함수입니다.
Key Parameter
위의 예시 코드에서 useAsyncData("item", ...) 의 첫 번째 파라미터로 전달한 "item"이 바로 key로, 데이터 요청을 고유하게 식별하는 값입니다. 여러 요청이 있을 때 각각을 구분하여 중복되지 않도록 보장하는 것이죠.
만약 key가 명시되지 않으면, Nuxt는 파일명과 useAsyncData 호출 라인 번호를 기반으로 자동으로 고유한 key를 생성합니다.
하지만 자동 생성된 키는 파일명과 호출된 줄 번호만 고려하므로, 예기치 않은 동작을 방지하려면 항상 직접 key를 지정하는 것이 좋습니다.
이 key는 Nuxt 내부에서 dedupe 옵션과 결합되어 HTTP 중복 호출을 막는 중요한 역할을 합니다.
Dedupe 옵션
useAsyncData는 중복된 HTTP 호출을 방지하기 위해 dedupe 옵션을 제공합니다. 이 옵션은 다음 두 가지 동작 방식을 가집니다:
- cancel: 새 요청이 들어오면 기존 요청을 취소하고 새로 요청을 처리합니다. (기본값)
- defer: 기존 요청이 진행 중이면 새로운 요청을 만들지 않고, 기존 요청이 완료될 때까지 대기합니다.
이를 통해 동일한 key를 가진 요청이 중복되지 않도록 하며, 서버와 클라이언트 간의 불필요한 데이터 요청을 방지하여 성능을 최적화합니다.
refresh
useAsyncData 내부의 refresh 함수는 데이터 요청을 효율적으로 관리하는 핵심 메서드로, 컴포넌트의 라이프사이클에 맞춘 최적화된 데이터 로딩을 처리합니다. 그 기능은 다음과 같이 요약할 수 있습니다:
1. 중복 요청 확인
nuxtApp._asyncDataPromises[key]를 사용해 동일한 key로 진행 중인 요청이 있는지 확인합니다.
진행 중인 요청이 있을 경우, dedupe 옵션에 따라 기존 요청을 취소할지(cancel) 또는 새로운 요청을 만들지 않을지(defer) 결정합니다.
2. 캐시된 데이터 반환
캐시된 데이터가 있는 경우, 서버에 새로 요청하지 않고 즉시 캐시 데이터를 반환하여 성능을 최적화합니다. 이는 key를 기반으로 데이터가 관리됩니다.
3. 상태 관리
데이터 요청의 상태를 관리하여 로딩 중(pending), 성공 여부, 또는 오류 발생 여부를 클라이언트에서 실시간으로 확인할 수 있습니다.
다음은 refresh 함수의 핵심 부분을 간단히 나타낸 코드입니다:
asyncData.refresh = asyncData.execute = (opts = {}) => {
// 중복 요청이 있으면, dedupe 옵션에 따라 처리
if (nuxtApp._asyncDataPromises[key]) {
if (isDefer(opts.dedupe ?? options.dedupe)) {
return nuxtApp._asyncDataPromises[key];
}
nuxtApp._asyncDataPromises[key].cancelled = true;
}
// 캐시된 데이터가 있으면 반환
if ((opts._initial || nuxtApp.isHydrating && opts._initial !== false) && hasCachedData()) {
return Promise.resolve(options.getCachedData(key, nuxtApp));
}
asyncData.pending.value = true; // 로딩 상태로 설정
asyncData.status.value = "pending"; // 상태 설정
};
이와 같은 로직을 통해 useAsyncData는 서버와 클라이언트 간의 중복된 HTTP 요청을 방지하고, 성능을 최적화합니다.
useAsyncData는 key, handler, dedupe 외에 options parameter 내부에 유용한 옵션들을 제공합니다.
useAsyncData Option Parameter
1. server: 데이터를 서버에서 가져올지 여부를 결정 (기본값: true)
false로 설정하면, 클라이언트 단에서 API 호출이 발생합니다.
2. lazy: 클라이언트 측 탐색을 차단하지 않고 라우트가 로드된 후에 비동기 함수를 실행할지 결정 (기본값: false)
요약만으로는 조금 이해가 어려울 수 있습니다. 예시를 통해 살펴보면 더 이해가 수월할 것입니다. 동일한 코드 실행 결과를 통해, 다른 페이지에서 메인 페이지로 라우팅하는 상황을 예로 들어 보겠습니다.
- lazy: false

lazy: false는 데이터가 모두 로드되기 전까지 라우트 로딩을 차단하는 방식입니다. 즉, 페이지에 필요한 모든 데이터를 가져온 후에야 화면을 렌더링합니다. 이 과정에서 사용자는 데이터를 모두 받을 때까지 빈 화면을 보게 됩니다.
이 방법은 데이터 로드가 완료되면 화면이 즉시 완전한 상태로 나타나므로, 화면 전환이 매끄럽게 보일 수 있지만, 데이터가 로드되는 시간이 길어지면 사용자 경험이 저하될 수 있습니다.
- lazy: true
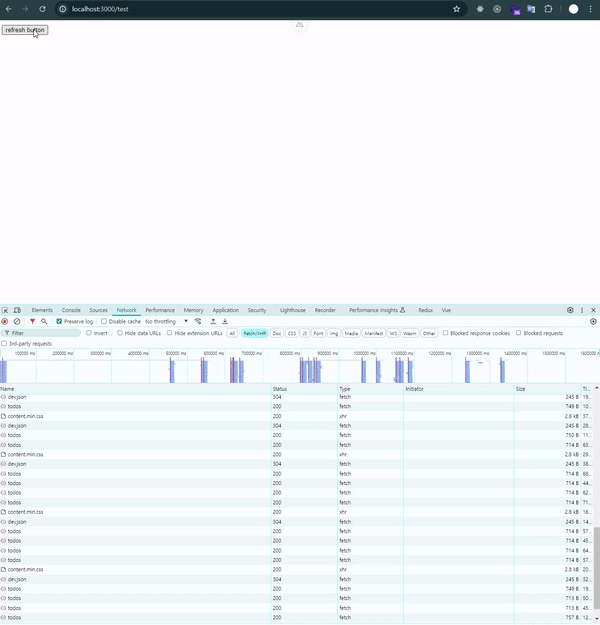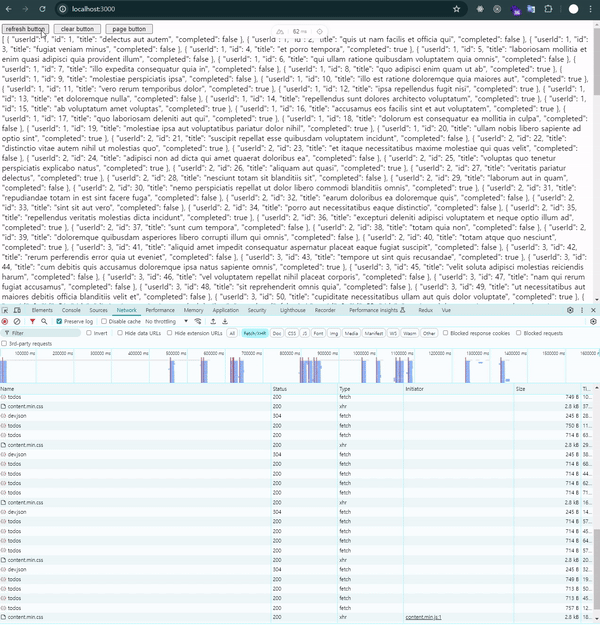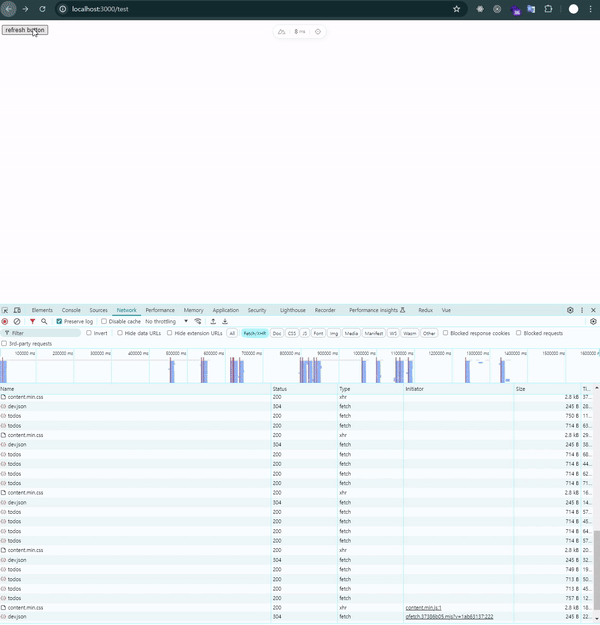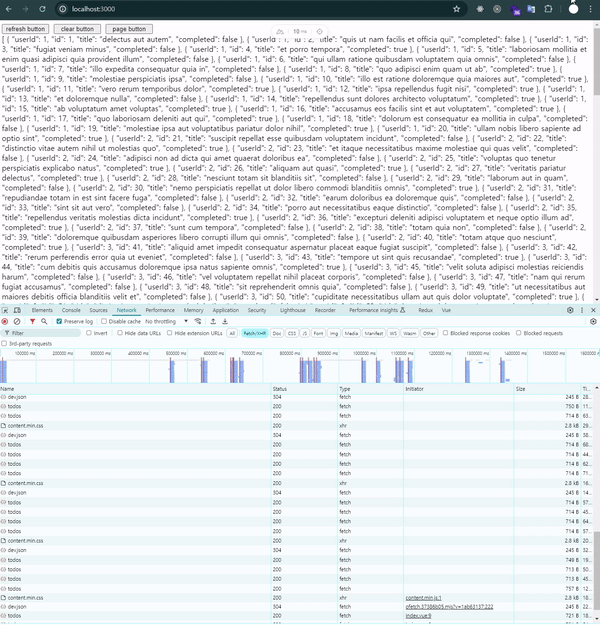
잠깐의 loading…메시지가 나오는 것이 보입니다.
lazy: true는 라우트가 로드된 후에도 데이터를 비동기적으로 처리하는 방식입니다. 즉, 페이지가 먼저 렌더링된 후 데이터를 비동기적으로 가져오기 때문에 화면 전환 속도는 빨라집니다.
하지만 데이터가 아직 준비되지 않았기 때문에 그 동안 로딩 상태를 표시해야 합니다. 사용자가 빠르게 페이지를 볼 수 있지만, 필요한 데이터가 로드될 때까지는 로딩 메시지나 스피너 같은 피드백을 제공해야 합니다.
따라서 로딩 상태를 적절히 구현할 수 있다면, lazy: true를 사용하는 방식이 더 나은 사용자 경험을 제공할 수 있습니다.
추가로, useLazyAsyncData를 사용하면 useAsyncData와 함께 lazy: true와 동일한 동작을 구현할 수 있습니다.
https://nuxt.com/docs/api/composables/use-lazy-async-data
useLazyAsyncData · Nuxt Composables
This wrapper around useAsyncData triggers navigation immediately.
nuxt.com
3. immediate: false로 설정하면 요청이 즉시 실행되지 않도록 설정(기본값: true)
이 옵션을 사용하면 사용자가 명시적으로 refresh 함수를 호출할 때까지 요청이 보류됩니다. 따라서 특정 상호작용 이후나 조건이 충족될 때만 데이터를 가져오고 싶을 때 유용하게 사용할 수 있습니다.
4. default: 비동기 함수가 해결되기 전에 데이터의 기본값을 설정
이 옵션은 lazy: true 혹은 immediate: false 옵션과 유용하게 사용될 수 있습니다.
- lazy: true일 때, 비동기 데이터를 가져오는 동안 빈 화면이 보일 수 있습니다. 이때 default로 기본값을 설정하면 로딩 중에도 기본 데이터를 표시하여 더 나은 사용자 경험을 제공합니다.
- immediate: false일 경우, 데이터 요청이 즉시 실행되지 않기 때문에, default 값을 미리 설정해두면 refresh 함수 호출 전까지 빈 화면을 방지할 수 있습니다.
이처럼 default 옵션을 사용하면, 로딩 중에도 UI의 기본 구조와 형식을 유지하며 안정적인 화면을 제공할 수 있습니다.
const { data, pending, error, refresh, clear } = await useAsyncData(
"item",
() => $fetch(`${getURL}/1`),
{
immediate: false, // or lazy: false
default: () => ({
userId: null,
id: null,
title: "loading...",
completed: false,
}),
}
);
5. transform: handler 함수의 결과를 변환하는 데 사용할 수 있는 옵션
transform 함수는 데이터에 추가적인 처리를 수행하거나 구조를 변경한 후 변환된 데이터를 반환합니다.
데이터 구조를 변경하거나, 특정 조건에 맞는 데이터를 필터링하거나, 추가적인 계산 및 가공을 수행하는 등 정말 유용하게 사용할 수 있는 옵션입니다.
const { data, pending, error, refresh, clear } = await useAsyncData(
"item",
() => $fetch(`${getURL}/1`),
{
transform: (data) => ({
userId: data.userId,
id: data.id,
title: data.title.toUpperCase(),
state: data.completed ? "completed" : "pending",
}),
}
);
6. getCachedData: 캐시된 데이터를 반환하는 함수를 제공. null 또는 undefined를 반환하면 페치가 트리거
이 부분은 Nuxt에서 다루는 캐시 개념과 깊게 연결되는데요, 따라서 여기서 다 정리하기에는 내용이 길어져 추후에 별도의 포스팅으로 소개하도록 하겠습니다.
7. pick: handler 함수의 결과에서 pick 배열에 지정된 키만 선택
pick 옵션을 활용해 불필요한 데이터를 필터링하고, 데이터 구조를 간결하게 유지할 수 있습니다.
const { data, pending, error, refresh, clear } = await useAsyncData(
"item",
() => $fetch(`${getURL}/1`),
{
pick: ["id", "title"],
}
);
8. watch: 자동 갱신을 위해 반응형 소스를 감시
watch 옵션을 설정하면, 지정된 반응형 소스가 변경될 때마다 자동으로 데이터를 업데이트할 수 있습니다.
이를 통해 동적인 데이터 요청이나 실시간 데이터 갱신과 같은 다양한 상황에서 데이터를 자동으로 업데이트하는 데 유용합니다.
const { data, pending, error, refresh, clear } = await useAsyncData(
"item",
() => $fetch(`${getURL}/${id.value}`),
{
watch: [id],
}
);
9. deep: ref 객체 내의 데이터 반응성을 제어(기본값: true)
기본적으로 이 옵션은 true로 설정되어 있어, 데이터가 깊은 반응형 객체로 반환됩니다. 이는 중첩된 속성이 변경될 때 자동으로 업데이트될 수 있게 해줍니다.
그러나 데이터가 깊은 반응성이 필요하지 않은 경우, deep 옵션을 false로 설정할 수 있습니다. 이렇게 하면 불필요한 중첩 속성 변화 추적을 방지하여 성능을 개선할 수 있으며, 특히 큰 데이터셋에서 유용합니다.
useAsyncData에 대한 더 자세한 내용은 Nuxt 공식문서에서 자세하게 확인할 수 있습니다.
https://nuxt.com/docs/api/composables/use-async-data
useAsyncData · Nuxt Composables
useAsyncData provides access to data that resolves asynchronously in an SSR-friendly composable.
nuxt.com
useFetch
useFetch는 useAsyncData와 $fetch를 편리하게 감싸주는 Composable입니다.
useFetch는 제공된 URL을 키로 사용합니다. 또는 마지막 인수로 전달된 options 객체에 key 값을 제공할 수도 있습니다.
useFetch의 반환 값은 useAsyncData와 같습니다
useFetch의 매개변수는 useAsyncData의 핸들러를 제외한 모든 파라미터와 $fetch의 옵션 파라미터를 포함합니다.
useFetch 메소드를 사용하면 인터셉터도 사용할 수 있습니다. 인터셉터를 통해 요청과 응답을 가로채고, 추가적인 처리를 할 수 있습니다.
const { data, pending, error, refresh, clear } = await useFetch('/api/auth/login', {
onRequest({ request, options }) {
// 요청 헤더 설정
options.headers = options.headers || {};
options.headers.authorization = '...';
},
onRequestError({ request, options, error }) {
// 요청 오류 처리
},
onResponse({ request, response, options }) {
// 응답 데이터 처리
localStorage.setItem('token', response._data.token);
},
onResponseError({ request, response, options }) {
// 응답 오류 처리
}
});
useFetch에 대한 더 자세한 내용은 Nuxt 공식문서에서 자세하게 확인할 수 있습니다.
https://nuxt.com/docs/api/composables/use-fetch
useFetch · Nuxt Composables
Fetch data from an API endpoint with an SSR-friendly composable.
nuxt.com
이쯤에서 한 가지 의문이 생기실 텐데요.
그래서 useAsyncData와 useFetch의 차이가 뭔데?
실제로 이 주제는 Nuxt 커뮤니티에서도 활발히 논의되고 있습니다. 저 역시 이 부분을 깊이 분석해보았습니다. useAsyncData와 useFetch의 차이점에 대해서는 추후의 포스트에서 더 자세히 다뤄보도록 하겠습니다.
'Nuxt.js' 카테고리의 다른 글
| [Nuxt3] 스마트한 API 호출 관리: Factory Pattern, 모듈화 (0) | 2024.10.24 |
|---|---|
| JWT in Nuxt3 (0) | 2024.09.03 |
| Caching in Nuxt3 (0) | 2024.07.30 |
| [Nuxt3] useAsyncData vs useFetch: 결정적 차이, 최적의 선택은? (0) | 2024.07.22 |
| Nuxt.js 렌더링 이해하기: 성공적인 웹 개발의 시작 (1) | 2024.07.06 |